
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- IvanLaptev
- vit
- Realtime
- DeepDoubleDescent #OpenAI #어려워
- XiaomingLiu #PersonIdentification
- 정리용 #하나씩읽고있음 #많기도많네 #내가찾는바로그논문은어디에
- centernet
- np-hard
- hourglass
- coco
- objectdetector
- Manmohan #UnconstrainedComputerVision
- CVPR
- ICCV19 #Real-World #FaceRecognition
- Transformer #classification #SOTA #Google
- cornernet #simple #다음은centernet #hourglass생명력이란
- POSE ESTIMATION
- Today
- Total
HyperML
RandAugment: Practical automated data augmentation with a reduced search space (google brain) 본문
RandAugment: Practical automated data augmentation with a reduced search space (google brain)
곰돌이만세 2020. 5. 29. 05:37
Introduction
- Data augmentation은 전문가의 손길과 설계 policy를 위해서는 매뉴얼한 조작이 필요합니다.
- 현재까지 소개되었던 학습가능한 augmentation policy 기법들은 정확도, 모델의 견고성과 성능을 높여주었습니다.
- NAS(Neural Architecture Search)기반의 최적화 방법은 더 나은 예측 성능을 높였으나 복잡성과 엄청난 계산량 요구때문에 기피되었습니다.
- 그래서 좀 더 효율적인 방식의 augmentation 함수의 탐색기법으로 AutoAugment(18.05, Google Brain), Fast AutoAugment(19.05 Kakao Brain) 같은 방식이 제안되었습니다.
- 그럼에도 불구하고 ML 모델의 학습에 여전히 비용이 많이 들었고, 복잡도가 높았습니다.
- 결론부터 말하면 여기서 모델의 data augmentation은 모델의 size와 학습셋의 size에 따른 최적 magnitude에 의존합니다.
쉽게 얘기하면 본 논문은 데이터셋이 크거나 모델사이즈가 큰 경우 augment의 함수(rotate, shear 등과 같은 operation)와 상관 없이 각 함수의 normalized 된 magnitude를 조절하면서 최적값을 간단히 찾을 수 있는 방법에 대해서 소개합니다.
AA vs FAA in GPU computation hours

현재까지 가장 발전되고 효율적인 learned augmentation 기법은 AA와 FAA인데 아직은 현실적이지 않은 cost를 보여줍니다. AA는 강화학습을 이용하여 operation을 최적화(operation 종류, 강도, 확률적인 빈도 등을 결정)하고 FAA는 베이지안 최적화를 사용합니다.
(5000 gpu x hour라는 말은 연산시간이 gpu1개일 때 5000시간 혹은 gpu가 5000개 일때 1시간이란 의미 입니다)
Search Space

AA, FAA는 위에서 소개드렸고, PBA는 Population Based Augment(ICML19, 19.05)로서 유전 알고리즘을 이용한 최적화로 augment 함수를 최적화 하는 기법입니다.
왜 많이들 사용하는 gradient descent like 기법을 사용하지 못하냐 하면, 뒤에 소개드릴 함수들 중에 일부는 미분불가능하기 때문입니다. 그래서 강화학습이나, 유전 알고리즘등의 다소 휴리스틱한 방법으로 최적화를 수행합니다.
Related Works
앞에서 간략하게 설명드렸지만 조금 자세하게 이전 논문들에 대한 소개를 드립니다.
AutoAugment

- RNN과 강화학습을 이용한 심플한 전략입니다. operation type, prob., magnitude 3가지를 최적화 합니다.
Population Based Augmentation

- 매 세대 마다 16개의 child model을 생성해서 평가후 살아남은 것을 다음 세대에 넘기는 전략입니다.
Fast AutoAugment

Method
- 실제 적용 방법은 매우 간단합니다. 아래 코드와 같이 코드를 만들고 grid search를 수행하면 됩니다.

- 간단하게 랜덤으로 구성된 operation 선택 funtion입니다. 모든 14개의 함수는 1/14확률로 call됩니다.(uniformly)
- 대상 operation 함수는 아래 그림에 있습니다. 흔히 사용하는 flip이 없는게 눈에 띕니다.

- Operation은 호출되는 횟수에 따라 K^N으로 표현됩니다.
- 그러므로 이전 AA나 FAA, PBA등에서 operation 및 prob. ,magnitude 까지 결정하기 위해 search space가 매우 컸다는 점을 생각해보면 매우 단순해진 형태입니다.
- Magnitude가 어떻게 normalize되는지를 보기 위해 저자들이 이전 논문인 AA에서의 op를 잠시 살펴 보겠습니다.

- 제일 오른쪽 컬럼이 normalize된 magnitude입니다.
- 이전 논문에서는 이 범위에서 정수인 0~10으로 결정했으나, 이번 RA(RandAugment)에서는 1~30으로 magnitude 범위를 좀 더 넓게 설정했습니다.
- 혹자는 이렇게 의심할 수도 있습니다. "기존의 learned augment 방식에서 operation관련 parameter 최적화를 위한 학습이나 반복과정에서 각각의 op에서의 magnitude가 변화할 수도 있지 않을까?"
- 하지만 아래 그래프 (PBA에서 가지고 옴) 보면 그렇지 않음을 알 수 있습니다.

- 학습이 진행되는 동안 각 operation들의 mag 비율은 크게 변화하지 않습니다. 그러므로 RA방식에서 초기에 지정한 각 op별 magnitude를 굳이 변화시키지 않아도 될 것으로 저자들은 생각했습니다.
- 또한 그렇다면 고정된 초기 magnitude를 결정함에 있어서 어떤 방식이 좋을지도 실험을 수행했습니다.

- 4가지 방식으로 실험을 수행하였는데 거의 차이를 보이지 않습니다.
- 따라서 가장 cost가 적은 Constant Magnitude가 선택되었습니다.
Experimets
- 기존의 AA, FAA 등에서는 augmentation된 결과를 데이터셋에 적용하기 위해 proxy task가 필수 였습니다.
- proxy task는 최적 augmentation policy를 찾기 위한 원래의 학습대상인 큰 데이터셋의 부분집합으로 구성한 작은 데이터셋을 가지고 최적화 작업을 진행하는 것을 의미합니다.
- 그런데 여기서의 가정은 작은 데이터셋에서 결정한 policy가 큰 데이터셋에서도 효과적이다 라는 것입니다
- 사실 그러한지 저자들은 실험을 수행했습니다. ( model size, dataset size )

(a) network size가 큰 것을 사용할 수록 acc가 높음을 알 수 있고 magnitude가 큰 값에서 결정됨을 알 수 있습니다.
(b) 좀 더 자세하게 보기 위해 최적 magnitude가 결정되는 구간을 WRN(Wide ResNet)의 widening param을 이용해서 (network size) 확인할 수 있습니다.
(c) 학습셋의 크기가 클 수록 magnitude가 큰 설정이 acc가 높음을 알수 있습니다.
(d) 학습셋의 크기가 클 수록 최적 magnitude가 단조증가 함을 알 수 있습니다.
- 사실 이런 부분들은 실험을 해보지 않고서는 알기가 힘든 부분입니다. magnitude의 범위가 아니라 고정된 magnitude를 크게 해서 큰 데이터셋이나 큰 네트워크 사이즈에 대응한다는 것은 직관적이지 않습니다.
- 여기서 여전히 magnitude를 개별로 관리하는 것이 더 낫지 않을까? 라는 생각을 할 수 있습니다.
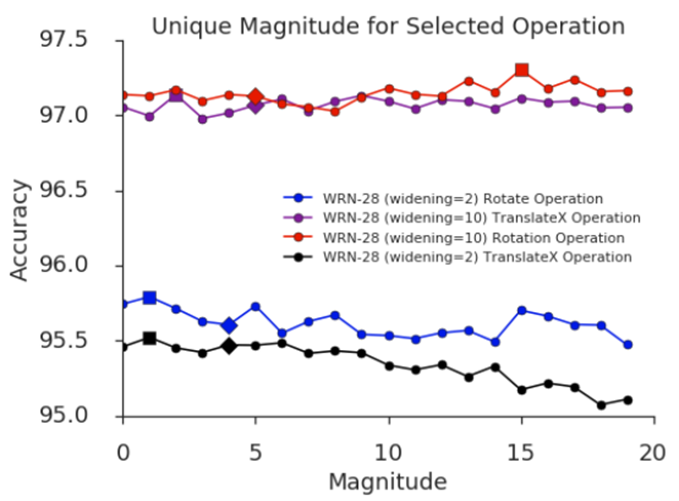
- 위 그래프에서 그렇지 않다라는 것을 보여줍니다. 14개의 op중 rotate, translate(shift) op의 mag만 변화시켰을 때 전체적인 acc변화양상을 보면 그렇게 차이가 나지 않음을 알 수 있습니다.
Test Results
CIFAR & SVHN
|
Dataset |
Network |
optimized N |
optimized M |
|
CIFAR-10 |
1 |
5 |
|
|
CIFAR-100 |
WRN-28-2 |
1 |
2 |
|
CIFAR-100 |
WRM-28-10 |
2 |
14 |
N = {1, 2}
M = {2, 6, 10, 14}
N은 op를 한번만 호출할지, 2번을 호출할지를
M은 magnitude 값을 어떻게 설정할지를 결정합니다.
- 이를 CIFAR-10, 100에 적용했을 때 위 실험 2 x 4 = 8번의 학습에서 찾아낸 최적 parameter가 표에 기록되어 있습니다.
- search space 10^2라고 되어 있으나 사실 간격을 두어 실험하면 그 보다 적은 횟수에서도 최적값을 찾아 낼 수 있습니다.

- 다른 방법들과의 성능비교 표 입니다. 매우 간단해진 계산 규칙에도 성능이 대등하거나 우월한 것을 불 수 있습니다.
ImageNet & COCO

- FAA의 경우 아예 ImageNet결과가 없습니다. 구글과 카카오의 차이인 것도 같은데, 구글 정도의 엄청난 GPU Power를 소유하지 않는 경우엔 ImageNet이나 COCO실험이 영원히 끝나지 않을 수도 있을 것 같습니다.
- RA가 여전히 제일 우수한 성능을 보여줍니다. CutOut도 ImageNet 실험을 수행했으나 성능향상엔 실패했다고 합니다.

- COCO에서의 실험은 AA가 더 우수합니다만 search space의 효율성에서는 서로간의 넘을 수 없는 벽이 있는 것을 알 수 있습니다.
- 이번엔 operation 별로 얼마나 기여하는가 깎아먹는가에 대한 내용입니다.

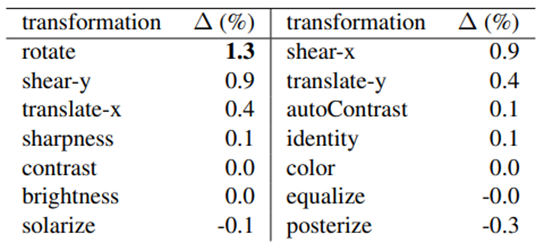
- 그래프를 보면 직관적으로 알 수 있습니다. 아래 표는 다른 모든 op 함수들에 대해 기여도를 알 수 있습니다.
- rotation이 가장 우수하고 posterize가 가장 좋지 않습니다.
- 이상으로 구글 브레인에서 발표한 RandAugment에 대해 알아 보았습니다.
- 구글 브레인 팀은 이 작업을 다른 ML 도메인에 대해서도 적용을 해보겠다고 말했습니다. (3D perception, speech recognition등) 기대해 보아도 좋을 것 같습니다.
읽어주셔서 감사합니다.
'논문읽기' 카테고리의 다른 글
| An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT) (0) | 2021.07.18 |
|---|---|
| Deep Double Descent (0) | 2019.12.09 |
| Pose estimation 정리 링크 (0) | 2019.10.22 |
| GAN link 모음 (0) | 2019.09.28 |
| [CVPR16]Thin-Slicing for Pose: Learning to Understand Pose without Explicit Pose Estimation (0) | 2019.09.27 |

