
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- vit
- Realtime
- CVPR
- cornernet #simple #다음은centernet #hourglass생명력이란
- np-hard
- hourglass
- POSE ESTIMATION
- XiaomingLiu #PersonIdentification
- IvanLaptev
- Transformer #classification #SOTA #Google
- Manmohan #UnconstrainedComputerVision
- 정리용 #하나씩읽고있음 #많기도많네 #내가찾는바로그논문은어디에
- DeepDoubleDescent #OpenAI #어려워
- coco
- objectdetector
- ICCV19 #Real-World #FaceRecognition
- centernet
- Today
- Total
목록논문읽기 (9)
HyperML
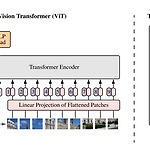 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT)
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ViT)
Transformer 는 본래 attention mechanisim 에 기반하여 language model의 학습을 위해 설계되었다. 간단한 구조와 적은 inductive bias 및 큰 weight capacity로 거대하게 모델을 만들고 거대한 데이터 학습에도 그 성능이 포화되지 않고, 언어모델의 self-supervised 학습 -> finetune 과정을 쉽게 수행함으로써 BERT, GPT와 같은 거대모델의 출현 및 다양한 task 활용을 이끌어 자연어 처리분야의 사실상 표준(de-facto standard)이 되었다. 이러한 transformer가 vision task에 적용될 것이라는 것은 누구나 예상할 수 있었고 많은 시도가 있었지만, ViT에 이르러서야 구글의 많은 데이터로 vision c..
 RandAugment: Practical automated data augmentation with a reduced search space (google brain)
RandAugment: Practical automated data augmentation with a reduced search space (google brain)
Introduction - Data augmentation은 전문가의 손길과 설계 policy를 위해서는 매뉴얼한 조작이 필요합니다. - 현재까지 소개되었던 학습가능한 augmentation policy 기법들은 정확도, 모델의 견고성과 성능을 높여주었습니다. - NAS(Neural Architecture Search)기반의 최적화 방법은 더 나은 예측 성능을 높였으나 복잡성과 엄청난 계산량 요구때문에 기피되었습니다. - 그래서 좀 더 효율적인 방식의 augmentation 함수의 탐색기법으로 AutoAugment(18.05, Google Brain), Fast AutoAugment(19.05 Kakao Brain) 같은 방식이 제안되었습니다. - 그럼에도 불구하고 ML 모델의 학습에 여전히 비용이 많이..
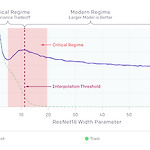 Deep Double Descent
Deep Double Descent
원문 : https://openai.com/blog/deep-double-descent/?fbclid=IwAR2kjb-SCR2wEWWlIKk3lnzVh9y_VYIInryB-DH7gBIcApi4xfdKRllnlx8 Deep Double Descent We show that the double descent phenomenon occurs in CNNs, ResNets, and transformers: performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. This effect is often avoided through careful op..
https://heartbeat.fritz.ai/a-2019-guide-to-human-pose-estimation-c10b79b64b73
김태오님 블로그 (pix2pix, cyclegan, discogan) https://taeoh-kim.github.io/blog/gan%EC%9D%84-%EC%9D%B4%EC%9A%A9%ED%95%9C-image-to-image-translation-pix2pix-cyclegan-discogan/ GAN을 이용한 Image to Image Translation: Pix2Pix, CycleGAN, DiscoGAN Computer Vision and Machine Learning Study Post 6 GAN을 이용한 Image to Image Translation: Pix2Pix, CycleGAN, DiscoGAN 줄기가 되는 Main Reference Paper입니다. Pix2Pix: Image-to-I..
 [CVPR16]Thin-Slicing for Pose: Learning to Understand Pose without Explicit Pose Estimation
[CVPR16]Thin-Slicing for Pose: Learning to Understand Pose without Explicit Pose Estimation
이전 포스팅(Greg Mori et al)에서 아쉬운 점으로 언급했던 부분들이 대거 보완되어 나온 논문 "일부의 joint가 image에 없거나, 가려지거나 몸통만 나오거나 등등의 사례에서는 어떨지. 그리고 어떻게 128x128 resize할 때 point는 어떻게 normalize 할지 이런 부분들도 언급이 없어서 아쉽다." 가장 큰 차이점은 위 논문에서 골반의 위치를 안다고 가정하고 있다는 점이지만 본 논문에는 그런것이 필요없다고 저자는 말하고 있다. 목적은 위와 유사하게 human pose가 들어있는 이미지 만으로 유사한 pose를 지닌 이미지를 DB에 query 하는 embedding 하는 것이다. joint 좌표는 없어도 된다. pose의 similarity를 구하는 것은 애초에 pose est..
 Pose Embedding: A Deep Architecture for Learning to Match Human Poses
Pose Embedding: A Deep Architecture for Learning to Match Human Poses
요약 : Human pose를 triplet loss로 embedding하여 query한 image와 가장 비슷한 human pose를 gallery(DB)에서 찾아주는 모델의 학습 및 방법 Deep Learning기법으로 거의 최초로 의미있는 human pose estimation 논문을 썼던 구글의 Alexander Toshev가 참여한 pose embedding 논문이다. 언뜻 보면 pose estimation에서 추출된 joint coordinate를 활용하는 것 같지만 본 모델에서 요구하는 것은 triplet sample뿐이다. 물론 뒤의 실험에서 triplet images + joint coordinates를 활용 했을 때 더 나은 성능을 보인다고는 하지만 어디까지나 본 논문이 추구하는 바는 ..
 [CVPR18]CosFace: Large Margin Cosine Loss for Deep Face Recognition
[CVPR18]CosFace: Large Margin Cosine Loss for Deep Face Recognition
먼저 읽어야 하는 paper : https://arxiv.org/pdf/1704.08063.pdf 얼굴인식의 정확도를 높이기 위한 페이퍼는 끝이 없이 나오는 것 같다. Alex와 Hinton이 ImageNet 논문을 NIPS에서 낸 12년도 이후 초기엔 CNN을 softmax classifier로 분류하다가 metric learning이 나오고 나서는 inter-class의 거리는 벌리고, intra-class끼리는 좁히는(둘 다 혹은 둘 중 하나만) center loss니 triplet loss니 하는 것들이 유행을 이끌었다. 이후 직각좌표 공간이 아닌 각좌표 공간을 도입한 논문이 나왔다. 얼굴 인식에 자주 사용되는 cosine similarity는 벡터간의 거리를 magnitude가 아닌 angle ..
 [CVPR17]Realtime Multi-Person 2D Pose Estimation using PAF
[CVPR17]Realtime Multi-Person 2D Pose Estimation using PAF
* 인트로덕션을 읽어보면 사람들은 크게 두가지 흐름으로 pose estimation 문제에 접근하는 것을 볼 수 있다. 하나는 top-down 방식, 나머지는 bottom-up 방식. * top-down 방식은 먼저 body detector로 검출한 범위내에서 part와 연결을 찾는 것이다. * bottom-up 방식은 이미지내에 여러사람들의 part를 다 찾고 타당한 연결을 찾는 식이다. * 본 논문은 bottom-up 방식을 취한다 * 네트워크는 조금 특이한데 기본적으로 종 방향으로는 part를 찾는 부분과 affinity field를 찾는 부분을 병렬로 구성하여 출력을 concat한다 * 횡방향으로는 앞부분에 VGG19 의 10layer만 써서 pretrain 된 것을 위치시키고, 뒷부분에 7x7이..