
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Realtime
- coco
- centernet
- Transformer #classification #SOTA #Google
- vit
- 정리용 #하나씩읽고있음 #많기도많네 #내가찾는바로그논문은어디에
- cornernet #simple #다음은centernet #hourglass생명력이란
- np-hard
- ICCV19 #Real-World #FaceRecognition
- IvanLaptev
- CVPR
- POSE ESTIMATION
- DeepDoubleDescent #OpenAI #어려워
- hourglass
- objectdetector
- Manmohan #UnconstrainedComputerVision
- XiaomingLiu #PersonIdentification
- Today
- Total
HyperML
Pose Embedding: A Deep Architecture for Learning to Match Human Poses 본문
요약 : Human pose를 triplet loss로 embedding하여 query한 image와 가장 비슷한 human pose를 gallery(DB)에서 찾아주는 모델의 학습 및 방법


Deep Learning기법으로 거의 최초로 의미있는 human pose estimation 논문을 썼던 구글의 Alexander Toshev가 참여한 pose embedding 논문이다.
언뜻 보면 pose estimation에서 추출된 joint coordinate를 활용하는 것 같지만 본 모델에서 요구하는 것은 triplet sample뿐이다. 물론 뒤의 실험에서 triplet images + joint coordinates를 활용 했을 때 더 나은 성능을 보인다고는 하지만 어디까지나 본 논문이 추구하는 바는 joint coordinate 없이 유사한 포즈를 찾아주는 것이다.
미리 정한 2가지 규칙에 따라 구성한 triplet samples를 다음과 같은 식으로 정리한다.
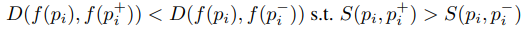
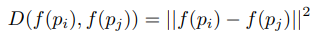
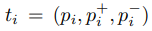
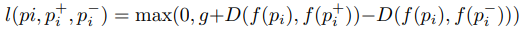
pi, pj는 각 human pose, f()는 embedding 함수, D() 두 sample에 대한 거리측정(L2 distance), S()는 두 sample에 대한 유사도 점수, ti는 triplet, l()는 gap을 부여하여 triplet을 적용한 hinge loss이다.

2015 당시 유행했던 inception-like한 구조를 그대로 가져왔고, 128x128로 resize한 human pose image를 128짜리 vector로 정리하였다. 두 샘플에 대해 이 벡터를 L2 distance한것이 결과가 된다.
데이터셋은 MPII Human Pose dataset을 사용했고 19919개의 image 중 10000개짜리 subset을 학습에 사용하고 나머지를 evaluation에 사용했다.
triplet을 사전 구성하기 위해,
positive pair는 서로의 모든 joint에 대해 평균 7 pixel 이하의 거리를 가질 때로 한정하였다.
negative pair는 5000 image 안에서 최소 15pixel이상으로 설정하였고, 이 경우 약 2000만개의 triplet이 생성되었다.
사지가 짧게 표현된 경우 정확도가 떨어질 수 있다고 함.
positive pair의 경우 의도적인 왜곡을 넣었음 scaling [0.9, 1.1]
batch size 600 AdaGrad, lr 0.05
실험:
학습에 사용하지 않은 MPII 9919 images 중 8000개를 database로 1919개를 query image로 사용
3가지의 서로 다른 성능 지표를 설정
1. Pose difference : K개까지의 query된 유사 이미지에 대해 Euclidean dist를 써서 실제로 얼마나 비슷한지 측정
2. Hit at K-absolute : 15pixel threshold mean joint dist.에 대해 실제로 correct 한 match인지 측정, K개중에 비율상 몇개의 correct match가 있는지 계수
3. Hit at K-relative : query image랑 가장 가까운 db내 이미지와의 거리를 tau라고 하면 tau+10 pixel까지 허용한 샘플들에 대해서 correct match의 비율
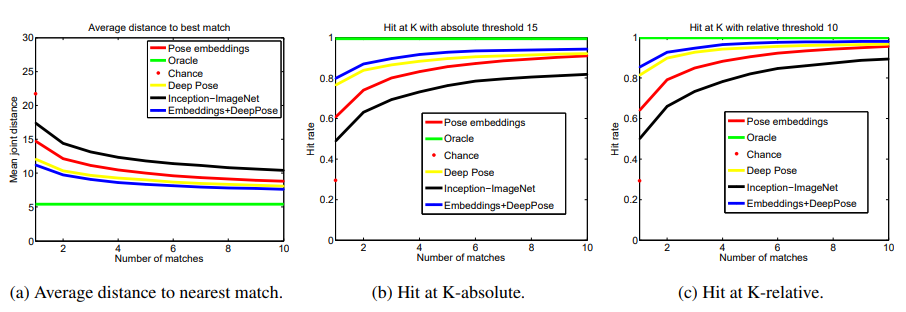
기존의 pose estimation 정보를 넣은 경우와의 성능비교가 있는데 그게 더 높다 본 모델 보다...
그러나 저자는 annotation을 joint마다 해줘야 하는 단점이 있다고 강조함.
어떻게 pose joint coord정보를 fuse했는지는 안나와 있는데 예상컨데 그냥 L2 dist에 128feature + 15joint coord. 를 했을 듯.
ImageNet으로 학습된 모델도 있는데, 이 경우 human의 pose보다는 다른 feature에 더 민감하게 반응했다고 한다. 예컨데, 싸이클 타는 image을 query하면 유사한 human pose한 image가 아닌 다른 pose로 싸이클 타는 image를 추출하는 식.
query 예:

첫 col이 query image, 나머지는 유사도가 높은 순으로 db에서 추출 된 이미지들
결론 :
단순한 아이디어로 쓰여진 논문이나 정성적으로 나쁘지 않는 성능을 보이는 듯 하다. 그러나 2015에 나온 논문이고 현실 세계에서 얼마나 잘 먹힐지는 실험을 해보아야 알 듯 하다.
일부의 joint가 image에 없거나, 가려지거나 몸통만 나오거나 등등의 사례에서는 어떨지. 그리고 어떻게 128x128 resize할 때 point는 어떻게 normalize 할지 이런 부분들도 언급이 없어서 아쉽다.
'논문읽기' 카테고리의 다른 글
| Pose estimation 정리 링크 (0) | 2019.10.22 |
|---|---|
| GAN link 모음 (0) | 2019.09.28 |
| [CVPR16]Thin-Slicing for Pose: Learning to Understand Pose without Explicit Pose Estimation (0) | 2019.09.27 |
| [CVPR18]CosFace: Large Margin Cosine Loss for Deep Face Recognition (1) | 2018.08.21 |
| [CVPR17]Realtime Multi-Person 2D Pose Estimation using PAF (236) | 2018.08.20 |


