
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- cornernet #simple #다음은centernet #hourglass생명력이란
- DeepDoubleDescent #OpenAI #어려워
- vit
- Realtime
- Transformer #classification #SOTA #Google
- XiaomingLiu #PersonIdentification
- objectdetector
- IvanLaptev
- hourglass
- 정리용 #하나씩읽고있음 #많기도많네 #내가찾는바로그논문은어디에
- centernet
- ICCV19 #Real-World #FaceRecognition
- np-hard
- coco
- Manmohan #UnconstrainedComputerVision
- POSE ESTIMATION
- CVPR
- Today
- Total
HyperML
[CVPR16]Thin-Slicing for Pose: Learning to Understand Pose without Explicit Pose Estimation 본문
[CVPR16]Thin-Slicing for Pose: Learning to Understand Pose without Explicit Pose Estimation
곰돌이만세 2019. 9. 27. 00:21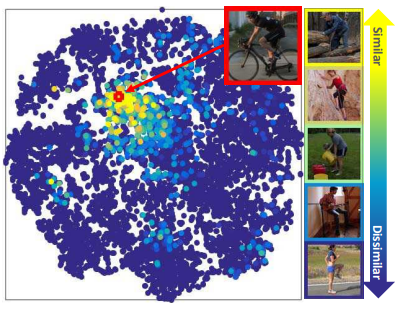
이전 포스팅(Greg Mori et al)에서 아쉬운 점으로 언급했던 부분들이 대거 보완되어 나온 논문
"일부의 joint가 image에 없거나, 가려지거나 몸통만 나오거나 등등의 사례에서는 어떨지. 그리고 어떻게 128x128 resize할 때 point는 어떻게 normalize 할지 이런 부분들도 언급이 없어서 아쉽다."
가장 큰 차이점은 위 논문에서 골반의 위치를 안다고 가정하고 있다는 점이지만 본 논문에는 그런것이 필요없다고 저자는 말하고 있다.
목적은 위와 유사하게 human pose가 들어있는 이미지 만으로 유사한 pose를 지닌 이미지를 DB에 query 하는 embedding 하는 것이다. joint 좌표는 없어도 된다.
pose의 similarity를 구하는 것은 애초에 pose estimation을 regression으로 구하는 논문들이 대다수 임을 볼 때 그 과정중에 모종의 기준들이 필요하나 그것을 어떻게 정하는 지에 대한 근거를 결정하기가 어렵다는 특징이 있다.
본 논문에서도 대략적인 기준들을 제시하고, 실제로 동작함을 보인다.
이전 논문과 유사한 역시 유사하게도 사용처(applicatoin)는 아래와 같다.
1. pose retrieval
2. pose-based fetature for action recognition
3. pose-based fetature for group activities
4. pose-based fetature for human object inter action analysis
loss는 triplet rank loss인데 full-body와 upper-body를 나눠서 embedding한다. network architecture는 공유한다
network는 VGG-S를 사용한다.

image를 224x224로 resize한 후 5개의 cnn을 거쳐서 fc1에서 2048 fc2에서 128 차원으로 줄인다
예전 cnn구조라서 7x7, 5x5짜리 conv연산이 있다.
Triplet rank loss
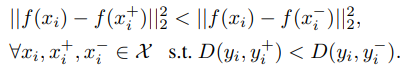
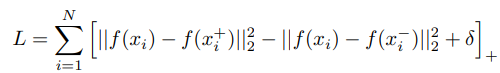
x는 anchor, x+는 positive sample, x-는 negative sample, 이들간의 거리는 pos pair끼리는 neg pair끼리보다 가까워야 하고 delta 만큼의 margin을 두어야 한다. 이를 l2norm으로 계산한 것을 Loss로 정의
Train Dataset
MPII Human Pose dataset을 사용했다. 25K images from YouTube video가 source이다.
25K중에 19919image를 annotation에서 fullbody로 찾아내서 사용하였고, 안보이는 joint라도 annotation이 있으면 있는 것으로 간주하였다.
H3D와 VOC2009 person에서 추가로 data를 수집했다. 적어도 12개의 joint가 있는 것을 활용했다.
최종 12366개의 image를 train에 사용했고, 9,919개의 이미지를validation에 사용했다.
Image and pose standarization
기존의 논문(Greg Mori et al)에서 골반(pelvis)를 기준점 삼아 pose image를 crop했는데 이것은 문제가 있다.
이를 추출하기 위해 testing time에 정확하고 명시적인 pose estimation을 요구한다는 점이다. 그래서 본 논문은 그냥 person detector를 사용했다. (아래 그림 참고)
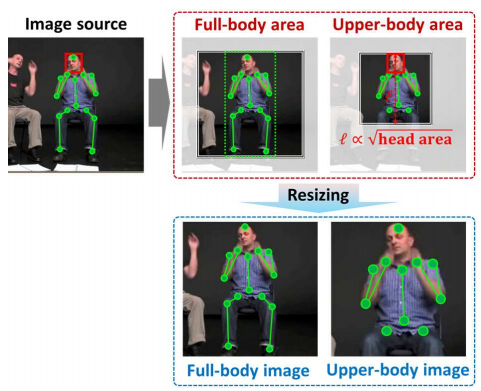
대신에 pose joint에 tight하게 붙여서 bounding box를 찾게 하고, 그를 커버하는 가장 작은 정사각박스를 결정했다.(full-body)
upper body의 경우 annotation된 head에 비례하는 bounding box를 찾았다. 이 경우 발목과 무릎은 무시했다.
Triplet Sampling
triplet을 구성하기 위해 pos. pair와 neg pair를 anchor를 기준으로 만든다. 엄청 많을 것이기 때문에 적당하게 샘플링한다. 어떤 흔한 포즈의 경우엔 pos pair가 대상 sample이 엄청 많을 것이고 어떤 pose는 아예 없을 수도 있다.

적당하게 걸러낸다 하더라도 너무 많을 것이라 어떤 기준이 필요한데 그것이 hard negative mining이다.
근데 이 경우 문제가 pose란 것이 상당히 연속적인 속성이 강해서, pos 와 neg의 기준이 모호할 수 있다는 점이다.
쉽게말하면 hard negative pair가 positive pair와 구분이 안될 수도 있다.
그러므로, hard negative minig 대신에 매 epoch마다 anchor에서 가장 먼 sample을 제거한다. 해당 샘플은 학습에 그다지 도움이 되지 않을 것이라는 가정에 기반한다.
진실인지 정확히는 알 수 없으나 성능에는 도움이 된다고 한다.
Learning network with random triplets
triplet을 미니배치안에서 생성
이해 x
Experiments
1. Pose retrieval on the MPII dataset
2. Action recognition on the VOC2012
3. Action recognition on the People Playing Musical Instruments(PPMI) dataset
Implementation details
Anchor 하나당 pos image를 30개로 고정 (full-body)
15개 (upper-body)
128 batch
5 randomly selected pos, 122 randomly selected negs.
neg pair는 매 epoch마다 3k가 제거되서 1K가 될 때까지 진행
image size는 임의로 +-10% scaling, 0.5 확률로 flipping
lr 0.01이고 매 epoch마다 0.2곱
momentum 기법 weight decay 0.9 and 0.0005
Manifold visualization

Pose retrieval
9919의 standarized image중 1919개가 선택되었음
K개의 가장 가까운 이웃의 평균 pose distance를 나타낸 지표 (아래 그래프)
(a) K개를 retrieve 했을 때의 평균
(b) K개를 retrieve 했을 때의 match 확률
(c) K개를 retrieve 했을 때의 nDCG값
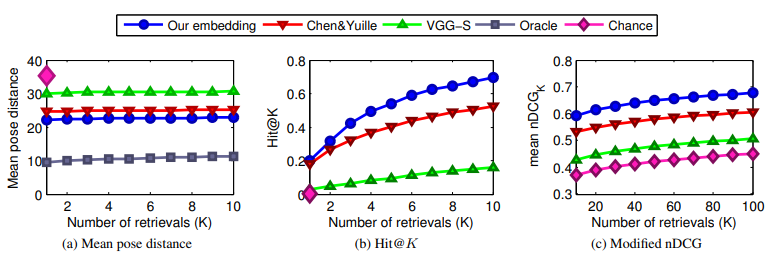
nDCG는 normalize discounted cumulative gain이고 아래 식과 같다.

높을 수록 retrieval이 의도대로 잘 된다는 것을 의미.
몇가지 예들.

조금 가려져도 그럭저럭 잘된다.

위 그림은 VOC2012 action 의 이미지를 query하고 얻은 결과이다
pose가 형태적으로 유사해 보이나 결국 다른 action인 경우가 대부분임을 알 수 있다.
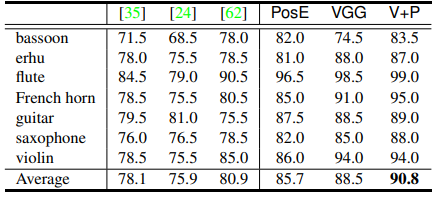
아래표는 각 action에 대해 AP를 얻은 것이다.
얻어진 embedding에 대해 SVM(RBF kernel)을 통해 classification하였다.
VGG 붙은 것은 ImageNet pretrained 된 모델을 가지고 와서 fc1,2를 거친 4096+4096=8192 vector 이다(VGG(img))
이것을 bounding box에 수행해서 얻은 feature를 동일하게 가지고 오면 8192 vector
둘을 concat하면 16384 vector


PPMI 평가
'논문읽기' 카테고리의 다른 글
| Pose estimation 정리 링크 (0) | 2019.10.22 |
|---|---|
| GAN link 모음 (0) | 2019.09.28 |
| Pose Embedding: A Deep Architecture for Learning to Match Human Poses (0) | 2019.09.26 |
| [CVPR18]CosFace: Large Margin Cosine Loss for Deep Face Recognition (1) | 2018.08.21 |
| [CVPR17]Realtime Multi-Person 2D Pose Estimation using PAF (236) | 2018.08.20 |

